

As Senior Manager for Automatic Speech Recognition (ASR) at Dialpad, I spend a lot of time considering ethics, diversity, and security issues tied to AI (artificial intelligence) and large language models.
One thing I consider is potential ethics issues that come into play when an AI model is trained on a limited (i.e., biased) dataset. For example, how will features for AI-powered tools possibly impact different people?
3 key ethical considerations in building AI
Addressing bias in AI tools
Some of the most accessible resources for training AI models are sourced from Western cultures—and the data tends to be weighted more toward men than women, even when it comes to nuances like slang. These biases impact the output of the tools using those models.
By over-indexing on a certain language, culture, or historical bias, an AI tool is limited in who it serves—and can even cause harm. Consider this example in a Towards Science Data article: An algorithm applied on more than 200 million people in US hospitals heavily favored white patients over Black patients when predicting who would likely need extra medical care. In another case, an algorithm used in US court systems misclassified Black offenders to be nearly twice as likely for recidivism than white offenders (45% vs. 23%).
Examples of AI getting it wrong are so prevalent that the topic is even being covered in popular culture. While this skit takes a humorous approach, the previous examples underscore the seriousness of the issue.
So, what does this have to do with our work related to AI-generated call transcriptions?
Say the data model behind the AI tool was trained on English language—and cultural norms—from a certain part of the US, like California.
Imagine an AI-powered call center transcription tool poorly captures an agent’s words because that person has a strong Australian English accent:
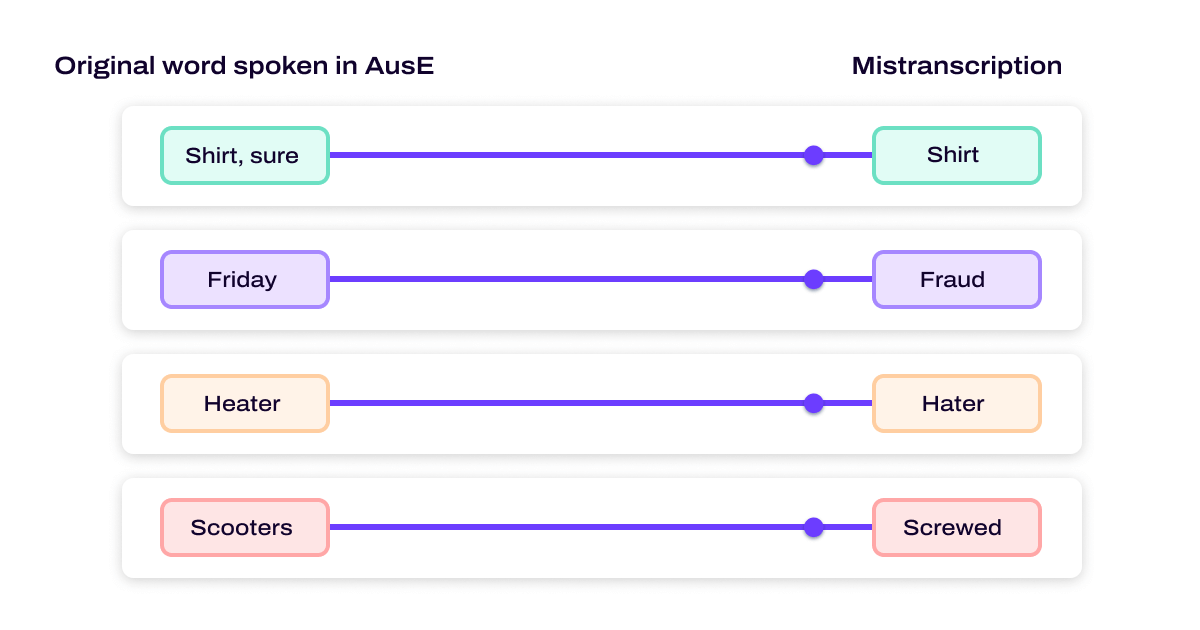
After reviewing the AI-generated transcript and considering subjective and cultural rules, such as “Was the agent polite?,” the call center manager might assign a low performance grade.
That poor grade might be due to the agent’s greeting being less traditional (such as “Hey!”) or mis-transcribed because of the regional accent. In other words, the performance grade will be inaccurate because of bias.
(If you use a QA scorecard tool that automatically suggests scores for agents based on AI analysis, this challenge is compounded even further because the AI must now be good enough to transcribe and analyze conversations accurately. That’s why this work is so important!)
📚 Further reading:
Learn more about AI transcription accuracy.
These situations illustrate the importance of not over-relying on AI, and for humans to step in when the results from AI seem off. Of course, it’s impossible to be 100% perfect. But it is possible to take steps to minimize such potential harm. At Dialpad, for example, we maintain an internal group that creates ethics guidelines to minimize such impacts and to identify opportunities to minimize bias before building features.
Representing diverse experiences and viewpoints
We've also found it helpful to formally convene around ethics issues to provide guidelines for tool development at Dialpad.
Some people believe automation can remove human bias. But bias appears in all data, so we need people who can identify the problem areas and blind spots that lead to bias. (This is a huge benefit of having a diverse team.)
In most cases, the people who are most able to see these potential sources of bias are the ones most negatively affected by them. By including people from various groups on product design and development teams, we can make it easier for these teams to effectively recognize how different groups will be impacted by any tool or feature—and minimize bias.
Diversity doesn’t just refer to background or race either—having folks with different experiences and forms of education can be valuable too.
It so happens that diversity breeds diversity. So, the more diversity on our team, the more inclined people representing various backgrounds and experiences are to join us. And that benefits both Dialpad and our customers!
Minimizing security risks
While more organizations are considering ethics and diversity when it comes to building ethical AI, one area that often gets overlooked is securing the data that flows through these tools.
At Dialpad, we only use customer data when our customers are comfortable with that fact. We allow them to readily revoke their consent and erase their data should they choose.
Knowing highly sensitive data can be relayed during the customer calls we transcribe, we take data security very seriously. We’ve found it helpful to have specialists on our AI data team ensure the integrity and security of our customers’ data, and make sure that data is used responsibly.
Your organization can take similar measures. For example, if you are using a third-party service to process your customer's data, you can minimize risk by anonymizing data before sending it to reduce the risk of sensitive data being intercepted. You could also strike strong contracts with your providers that confirm they treat the data as securely as your organization would and won’t retain your data longer than necessary.
A checklist for getting started with ethical AI
In addition to incorporating some of the suggestions I included throughout this post, your organization could benefit by observing these helpful tips when designing, developing, and deploying your AI tool or feature.
First, before you even start development of a new feature, try to envision where or how it could fail or cause harm. To do that, you’ll need to outline first how you expect it to be used. Examples of questions to ask here:
Who is the audience?
What type of language are they using—not just English vs. Mandarin, but also is the language more formal or casual?
Are they using industry-specific jargon?
Next, consider what could go wrong. If your feature were to perform poorly in general or on a specific demographic group, what would that look like? A few key considerations:
Would it be obvious to the end user that something is off?
Will people be making decisions based on your output that could cause a major disturbance in someone's life (like if they get a job, or a mortgage, or parole)?
Then similarly to how we protect from injection attacks think of how users may try to intentionally abuse your feature. Especially if you have a public-facing API, are you limiting the potential outputs of your system to prevent leaking other customer’s data or potentially dangerous information?
💡 What are injection attacks?
When an end user can input their own text into a program (like ChatGPT!), if the developer does not put up guardrails or checks, the user could insert code to do a number of different things. For example, someone could ask an LLM to output information that it may have access to, like company secrets or code.
Once you’ve documented these details, think through mitigation strategies for these potential harms, as well as how you’ll handle PII and other sensitive data. For example:
Can you include a human in the loop to assess automated scoring
Can you use debiasing techniques if you have to use a skewed dataset?
Could you remove PII (Personally Identifiable Information) before annotation, or take other steps to keep data safe?
Note that if you decide a feature might cause harm to people in a certain region, you could decide to release it only in the region where you have sufficient training data. Then you can plan to release in the other region once you can mitigate the harm.
When you’ve built something, make sure you take the time to properly test and evaluate it on different types of data:
Does the model do better on certain inputs (e.g. does your question detection model do much better on 5Ws questions vs yes/no questions)?
How does it perform on different demographic slices—is the model much better for men vs. women or native English speakers vs those with foreign accents?
How does it perform on data that is very different from your training data?
Once you have all the data and before you deploy you can assess whether biases in the model could cause harm if you proceed. You may decide:
This bias isn’t likely to directly harm particular groups or
Releasing the feature will be more beneficial than detrimental to our customers or
The necessary improvements are documented and slated for future quarters
No one can predict every possible outcome for every possible model, and unforeseen ethical issues can happen despite best efforts. That’s why you should continue to monitor your model’s performance after deployment. Doing so will position you to address any such issues that may arise, including deciding when to retrain your model.
What measures does your organization take to address ethics and security in its AI tools?
Get a hands-on look at Dialpad Ai
From uncovering more customer intelligence, to coaching your sales reps and support agents through tough calls in real time, Dialpad Ai is helping businesses have more productive and more efficient conversations. Learn more with a demo, or take a self-guided interactive tour of the app first!